Si vous développez un projets sur le framework .NET "classique", et que vous avez décidé de passer à .NET Standard pour les projets liés, vous avez peut-être eu droit à une erreur FileNotFoundException au chargement d'une dll (utilisée par votre projet .NET Standard) - vous obligeant à référencer le package Nuget en question directement depuis l'application appellante.
Depuis quelques temps, les développeurs .NET peuvent utiliser un nouveau format de fichier .csproj (et pour les développeurs Visual Basic, tout ce que j'explique ici à propos des csproj s'applique aussi aux vbproj), dans les projets .NET Core ou .NET Standard.
Voici par exemple les 2 formats de csproj, l'un étant un projet console en .NET classique, l'autre en .NET Core :
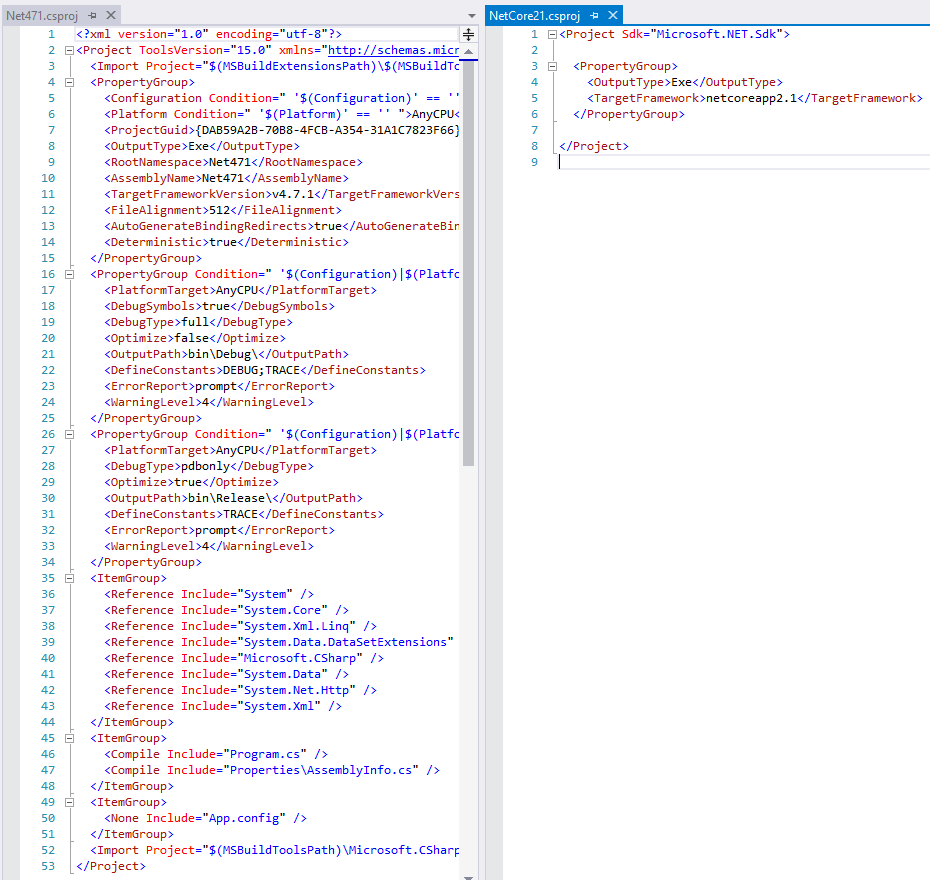
Outre le gain évident en terme de lisibilité, le nouveau format apporte une nouvelle gestion des packages Nuget. Voyons comment tout ça fonctionne maintenant.
L'ancien fonctionnement : le fichier packages.config
Si vous êtes développez avec l'ancien format csproj, lorsque vous référencez un package Nuget, il est ajouté dans le fichier packages.config, qui se trouve à la racine du projet.
<?xml version="1.0" encoding="utf-8"?>
<packages>
<package id="Newtonsoft.Json" version="12.0.1" targetFramework="net471" />
</packages>
Si le package en référence d'autres, toutes les dépendances seront ajoutées dans ce fichier. On peut donc très vite arriver à un assez grand nombre de packages référencés ici.
Le fonctionnement de Nuget est ensuite très simple : il va télécharger le package et le mettre dans un dossier packages, situé au même niveau que le sln. Il va ensuite modifier le csproj pour ajouter la référence vers la ou les dll. Ces dll seront ensuite copiées dans le répertoire de destination en même temps que le projet.
Le nouveau fonctionnement :
La refonte du format csproj a été l'occasion d'améliorer la gestion des packages, et donc de gérer Nuget nativement. Cette fois, plus de fichier packages.config, si vous référencez un package il est directement ajouté dans le csproj en tant que package :
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp2.1</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Newtonsoft.Json" Version="12.0.1" />
</ItemGroup>
</Project>
Contrairement à l'ancien csproj, où toutes les références étaient des liens vers des dll, ici on sait que la référence vient de Nuget quand on utilise la balise <PackageReference>.
Autre différence avec l'ancien format : nous n'avons plus le dossier packages. Maintenant, les dll sont téléchargées dans le profil utilisateur (allez jeter un œil dans %userprofile%\.nuget\packages sur votre disque dur pour voir la liste), et elles ne sont pas copiées dans l'output lors de la compilation.
Utiliser les deux à la fois
Si vous avez des projets .NET Standard référencés par un projet .NET classique, vous allez vous retrouvez avec les 2 systèmes à la fois, qui ne sont pas vraiment compatibles, et c'est ce qui va causer la FileNotFoundException.
Supposons que votre projet .NET Standard référence Newtonsoft.Json. Il utilise le nouveau Nuget, et ne va pas copier la dll dans l'output.
Votre projet .NET classique lui utilise toujours l'ancien système de références de projets : il va récupérer l'output de l'autre projet, mais ne récupèreras donc pas Newtonsoft.Json. Et donc, lorsque vous aurez besoin de sérialiser des données à l'exécution, ça plante.
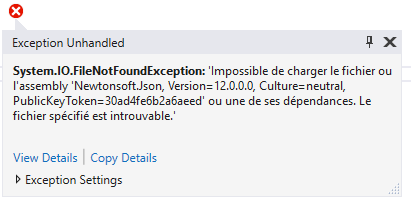
Un moyen simple de réparer ce problème est de simplement ajouter le package Nuget dans le projet principal, pour être sûr qu'il le récupère. Mais il y a mieux.
Utiliser PackageReference dans l'ancien csproj.
En fait, il est possible d'utiliser les
Migrate from packages.config to PackageReference.
Attention, ça ne fonctionne que dans Visual Studio 2017 (v 15.7 minimum), et les projets C++ et ASP.NET ne sont pas encore supportés.
Pour utiliser PackageReference, il suffit d'ajouter <RestoreProjectStyle>PackageReference</RestoreProjectStyle> dans le csproj :
</PropertyGroup>
<RestoreProjectStyle>PackageReference</RestoreProjectStyle>
</PropertyGroup>
Attention, si vous avez déjà un packages.config, il faut désinstaller tous les packages avant de les remettre. Visual Studio 2017, vous propose de le faire automatiquement, il suffit de faire un clic droit sur le fichier packages.config, et cliquer sur "Migrate packages.config to PackageReference".
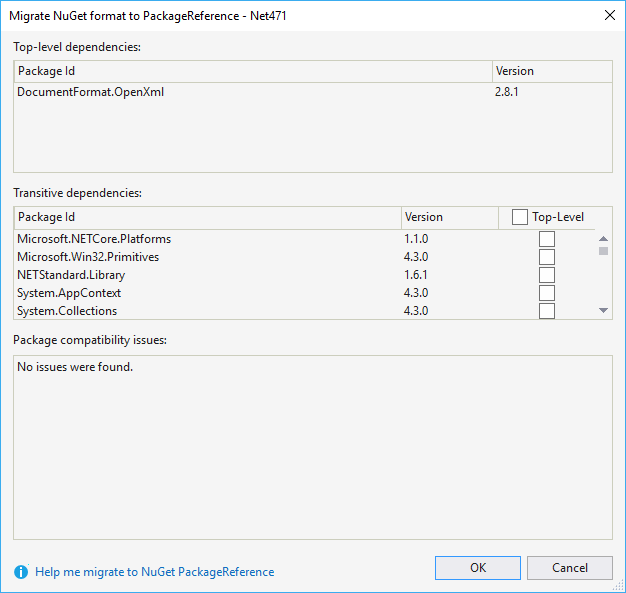
Si tout se passe bien, ça marchera du premier coup (sinon bon courage pour débuguer les conflits de version). Une fois sur le nouveau Nuget, vous ne devriez plus avoir de soucis de fichiers manquants.